🧮SVM
Apa itu SVM?
Support Vector Machines (SVM) adalah salah satu metode pembelajaran terbimbing (supervised learning) pada pembelejaran mesin yang dikenal dengan kemampuannya yang baik dan fleksibel untuk menyelesaikan kasus klasifikasi dan regresi. Penerapan SVM dilakukan melalui pembelajaran sebuah model yangs sederhana yang berfungsi untuk mengembangkan model yang generatif dalam rangka menentukan label dari titik atau data baru secara probabilistik.
Tujuan dari algoritma SVM adalah untuk menemukan hyperplane dalam ruang berdimensi N (N — jumlah fitur) yang mengklasifikasikan titik data secara jelas.
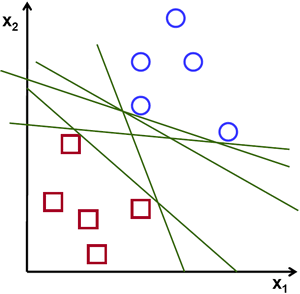
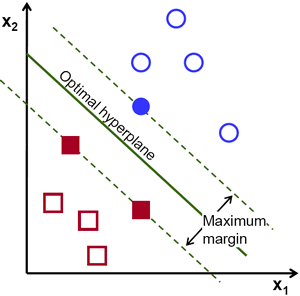
Untuk memisahkan kedua kelas titik data tersebut, ada banyak kemungkinan hyperplane yang dapat dipilih. Tujuan kita adalah mencari bidang yang mempunyai margin maksimum, yaitu jarak maksimum antara titik data kedua kelas. Memaksimalkan jarak margin memberikan beberapa penguatan sehingga titik data di masa depan dapat diklasifikasikan dengan lebih percaya diri.
Hyperplanes dan Support Vector
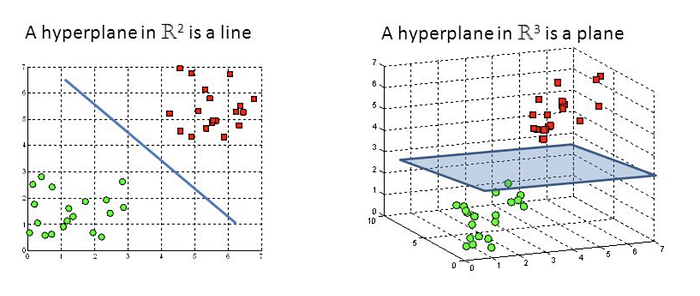
Hyperplanes adalah batasan keputusan yang membantu mengklasifikasikan titik data. Titik data yang berada di kedua sisi hyperplane dapat dikaitkan ke kelas yang berbeda. Selain itu, dimensi hyperplane bergantung pada jumlah fitur. Jika jumlah fitur masukan adalah 2, maka hyperplane hanyalah sebuah garis. Jika jumlah fitur masukan adalah 3, maka bidang hiper menjadi bidang dua dimensi. Sulit membayangkan bila jumlah fitur melebihi 3.
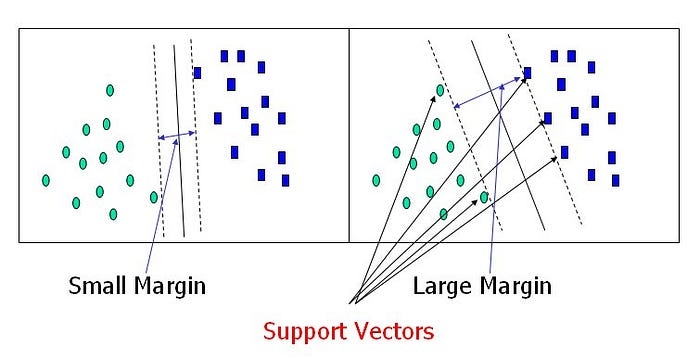
Support Vector adalah titik data yang lebih dekat dengan hyperplane dan mempengaruhi posisi serta orientasi hyperplane. Dengan menggunakan Support Vector ini, garis margin pengklasifikasi dapat dimaksimalkan. Menghapus support vector akan mengubah posisi hyperplane. Inilah poin-poin yang dipakai untuk membangun SVM.
Last updated
Was this helpful?