🧰Dasar Teori
sumber : https://www.analyticsvidhya.com/blog/2022/03/a-brief-overview-of-recurrent-neural-networks-rnn/
Pengantar Jaringan Neural Berulang
Pendekatan Deep Learning untuk memodelkan data sekuensial adalah Recurrent Neural Networks (RNN) . RNN adalah model yang biasa digunakan untuk bekerja dengan data sekuensial sebelum munculnya model Attensi. Parameter spesifik untuk setiap elemen urutan mungkin diperlukan oleh model umpan maju yang mendalam. Mungkin juga tidak dapat menggeneralisasi sequence dengan panjang yang bervariasi.
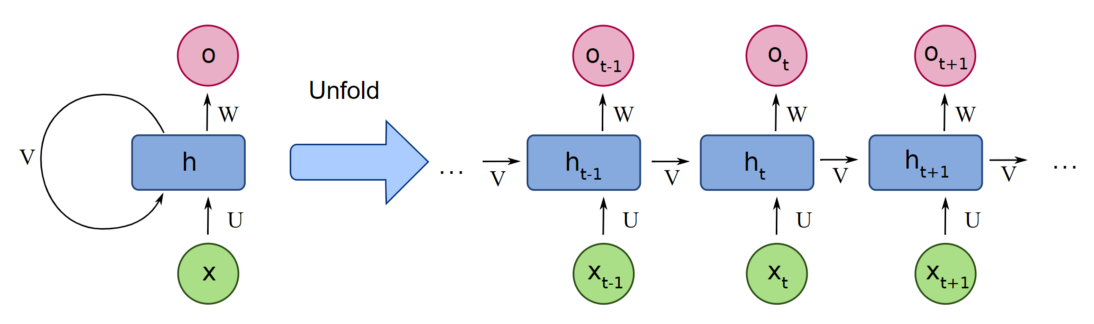
Jaringan Neural Berulang menggunakan bobot yang sama untuk setiap elemen rangkaian, sehingga mengurangi jumlah parameter dan memungkinkan model untuk menggeneralisasi ke sequence dengan panjang yang bervariasi. RNN menggeneralisasi data terstruktur selain data sekuensial, seperti data geografis atau grafis, karena desainnya.
Jaringan saraf berulang, seperti banyak teknik pembelajaran mendalam/deep learning lainnya, merupakan model lama. Mereka pertama kali dikembangkan pada tahun 1980an, namun belum disadari potensi penuhnya hingga akhir-akhir ini. Munculnya memori jangka pendek (LSTM) pada tahun 1990an, dikombinasikan dengan peningkatan daya komputasi dan banyaknya data yang harus kita tangani, telah benar-benar mendorong RNN menjadi yang terdepan.
Apa itu Jaringan Neural Berulang (RNN)?
Jaringan saraf meniru fungsi otak manusia di bidang AI, pembelajaran mesin, dan pembelajaran mendalam, memungkinkan program komputer mengenali pola dan memecahkan masalah umum.
RNN adalah jenis jaringan saraf yang dapat digunakan untuk memodelkan data urutan. RNN, yang dibentuk dari jaringan feedforward, memiliki perilaku yang mirip dengan otak manusia. Sederhananya, jaringan saraf berulang dapat mengantisipasi data berurutan dengan cara yang tidak dapat dilakukan oleh algoritma lain.
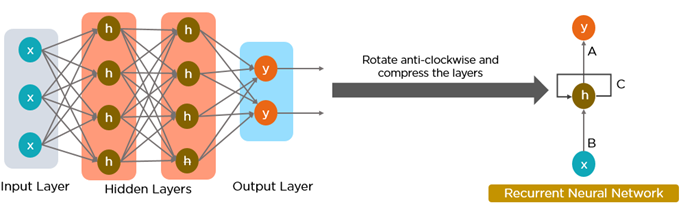
Semua masukan dan keluaran dalam jaringan saraf standar tidak bergantung satu sama lain, namun dalam keadaan tertentu, misalnya saat memprediksi kata berikutnya dalam suatu frasa, kata-kata sebelumnya diperlukan, sehingga kata-kata sebelumnya harus diingat. Hasilnya, dibuatlah RNN yang menggunakan Lapisan Tersembunyi untuk mengatasi masalah tersebut. Komponen terpenting dari RNN adalah status Tersembunyi, yang mengingat informasi spesifik tentang suatu urutan.
RNN memiliki Memori yang menyimpan semua informasi tentang penghitungan. Ia menggunakan pengaturan yang sama untuk setiap masukan karena menghasilkan hasil yang sama dengan melakukan tugas yang sama pada semua masukan atau lapisan tersembunyi.
Arsitektur RNN Tradisional
RNN adalah jenis jaringan saraf yang memiliki status tersembunyi dan memungkinkan keluaran masa lalu digunakan sebagai masukan. Biasanya seperti ini:
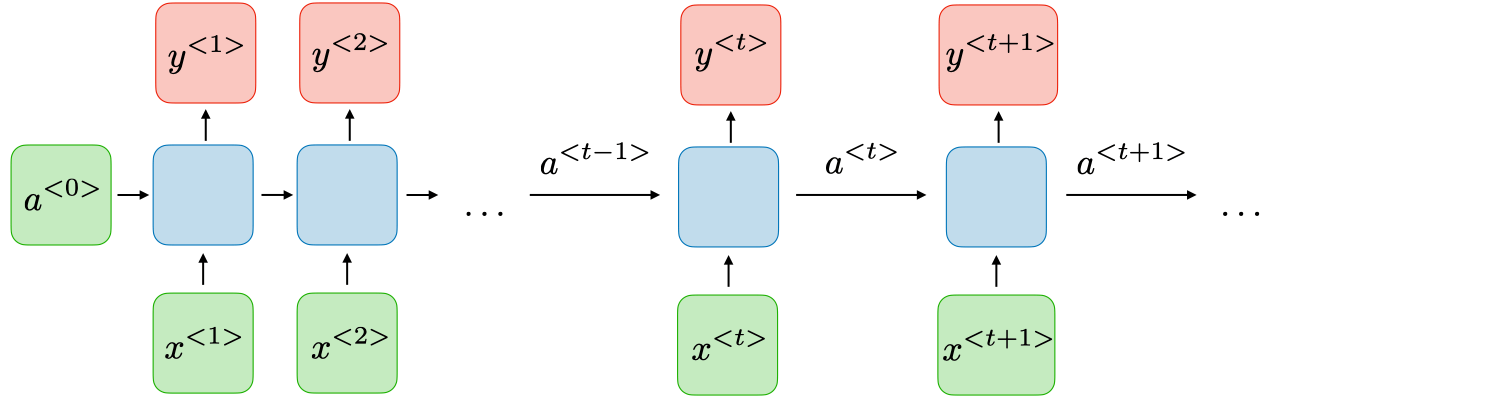

Arsitektur RNN dapat bervariasi tergantung pada masalah yang Anda coba selesaikan. Dari yang memiliki input dan output tunggal hingga yang memiliki banyak (dengan variasi antar).
Berikut adalah beberapa contoh arsitektur RNN yang dapat membantu Anda lebih memahami hal ini.
One To One: Hanya ada satu pasangan di sini. Arsitektur satu-ke-satu digunakan dalam jaringan saraf tradisional.
Satu Ke Banyak: Satu masukan dalam jaringan satu-ke-banyak dapat menghasilkan banyak keluaran. Misalnya, terlalu banyak jaringan yang digunakan dalam produksi musik.
Many To One: Dalam skenario ini, satu keluaran dihasilkan dengan menggabungkan banyak masukan dari tahapan waktu yang berbeda. Analisis sentimen dan identifikasi emosi menggunakan jaringan seperti itu, di mana label kelas ditentukan oleh rangkaian kata.
Banyak Ke Banyak: Bagi banyak ke banyak, ada banyak pilihan. Dua masukan menghasilkan tiga keluaran. Sistem terjemahan mesin, seperti sistem terjemahan Bahasa Inggris ke Bahasa Prancis atau sebaliknya, menggunakan banyak ke banyak jaringan.
Bagaimana cara kerja Jaringan Neural Berulang?
Informasi dalam jaringan saraf berulang berputar melalui loop ke lapisan tengah yang tersembunyi.

Lapisan masukan x menerima dan memproses masukan jaringan saraf sebelum meneruskannya ke lapisan tengah.
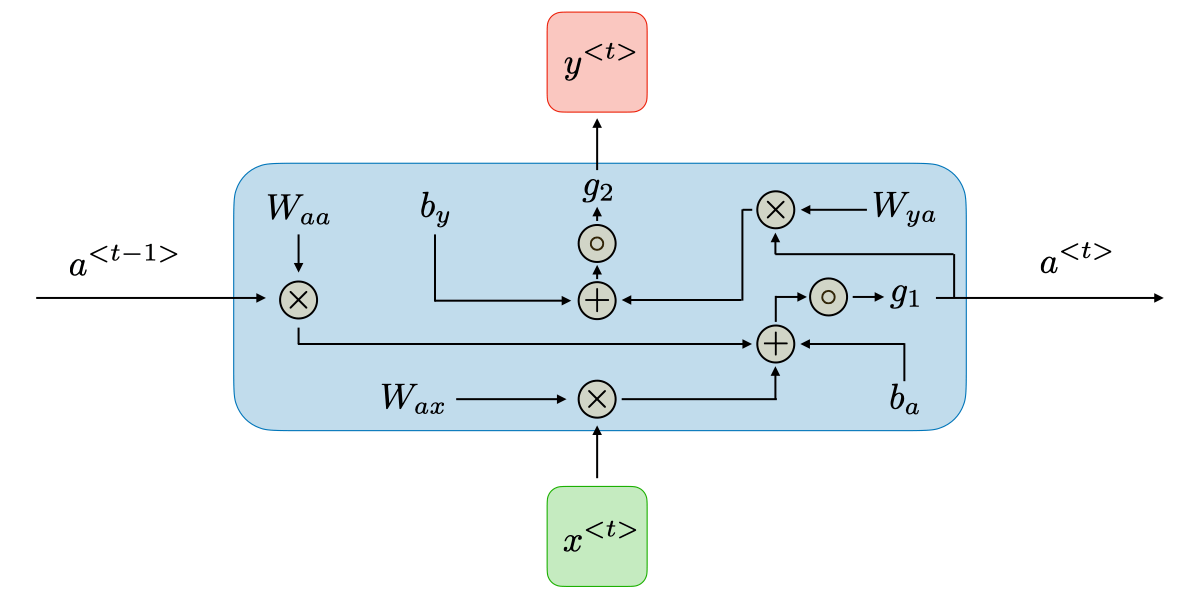
Beberapa lapisan tersembunyi dapat ditemukan di lapisan tengah h , masing-masing dengan fungsi aktivasi, bobot, dan biasnya sendiri. Anda dapat memanfaatkan jaringan saraf berulang jika berbagai parameter lapisan tersembunyi yang berbeda tidak terpengaruh oleh lapisan sebelumnya, yaitu Tidak ada memori di jaringan saraf.
Fungsi aktivasi, bobot, dan bias yang berbeda akan distandarisasi oleh Recurrent Neural Network, untuk memastikan bahwa setiap lapisan tersembunyi memiliki karakteristik yang sama. Daripada membuat banyak lapisan tersembunyi, ini hanya akan membuat satu lapisan dan mengulanginya sebanyak yang diperlukan.
Fungsi Aktivasi Umum
Fungsi aktivasi neuron menentukan apakah neuron harus dihidupkan atau dimatikan. Fungsi nonlinier biasanya mengubah keluaran neuron menjadi angka antara 0 dan 1 atau -1 dan 1.
Berikut ini adalah beberapa fungsi yang paling umum digunakan:
Sigmoid: Rumus g(z) = 1/(1 + e^-z) digunakan untuk menyatakan hal ini.
Tanh: Rumus g(z) = (e^-z – e^-z)/(e^-z + e^-z) digunakan untuk menyatakan hal ini.
Relu: Rumus g(z) = max(0 , z) digunakan untuk menyatakan hal ini.
Jaringan Neural Berulang Vs Jaringan Neural Feedforward
Jaringan saraf feed-forward hanya memiliki satu rute aliran informasi: dari lapisan masukan ke lapisan keluaran, melewati lapisan tersembunyi. Data mengalir melintasi jaringan dalam rute yang lurus, tidak pernah melewati node yang sama dua kali.
Aliran informasi antara RNN dan jaringan saraf feed-forward digambarkan dalam dua gambar di bawah.
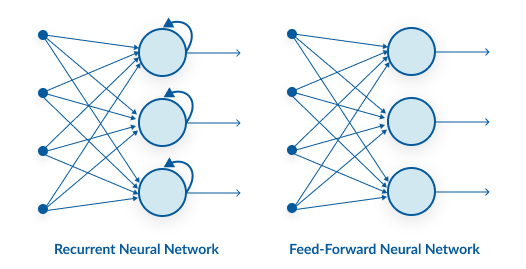
Jaringan saraf feed-forward merupakan prediksi yang buruk tentang apa yang akan terjadi selanjutnya karena mereka tidak memiliki memori atas informasi yang mereka terima. Karena hanya menganalisis input saat ini, jaringan feed-forward tidak mengetahui urutan waktu. Selain pelatihannya, ia tidak memiliki ingatan tentang apa yang terjadi di masa lalu.
Informasinya ada dalam siklus RNN melalui loop. Sebelum membuat keputusan, ia mengevaluasi masukan saat ini serta apa yang telah dipelajari dari masukan sebelumnya. Sebaliknya, jaringan saraf berulang mungkin dipanggil kembali karena memori internal. Ini menghasilkan keluaran, menyalinnya, dan kemudian mengembalikannya ke jaringan.
Propagasi Balik Melalui Waktu (BPTT)
Saat algoritma Backpropagation diterapkan ke Jaringan Neural Berulang dengan data deret waktu/time series sebagai masukannya, kami menyebutnya propagasi mundur melalui waktu.
Satu masukan dikirim ke jaringan pada satu waktu di RNN normal, dan satu keluaran diperoleh. Propagasi mundur, di sisi lain, menggunakan masukan saat ini dan masukan sebelumnya sebagai masukan. Hal ini disebut sebagai langkah waktu, dan satu langkah waktu akan terdiri dari beberapa titik data deret waktu yang memasuki RNN secara bersamaan.
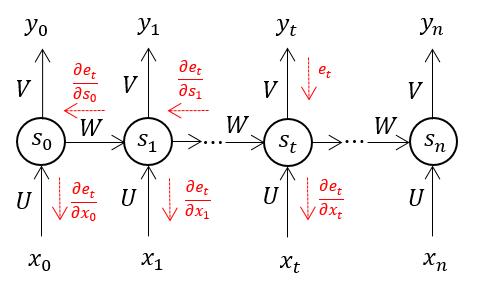
Keluaran jaringan saraf digunakan untuk menghitung dan mengumpulkan kesalahan setelah jaringan tersebut dilatih pada waktu yang ditentukan dan memberi Anda keluaran. Jaringan kemudian digulung kembali, dan bobot dihitung ulang dan disesuaikan dengan memperhitungkan kesalahan.
Dua edisi RNN Standar
Ada dua tantangan utama yang harus diatasi oleh RNN, namun untuk memahaminya, pertama-tama kita harus memahami apa itu gradien.
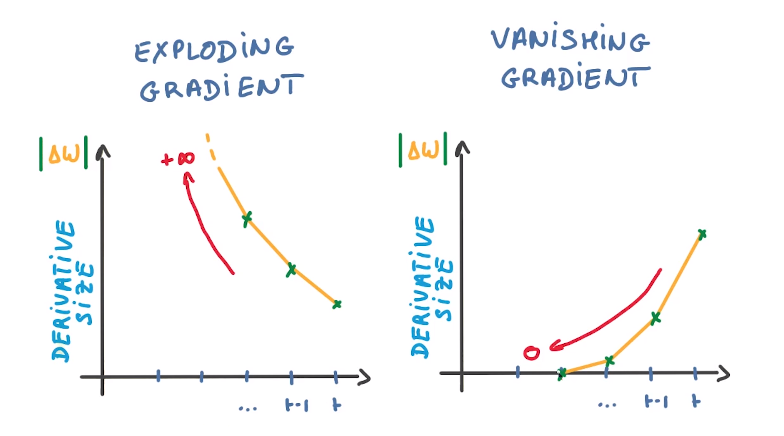
Berkenaan dengan masukannya, gradien merupakan turunan parsial. Jika Anda tidak yakin apa implikasinya, pertimbangkan ini: gradien mengkuantifikasi seberapa besar variasi keluaran suatu fungsi ketika masukannya diubah sedikit.
Kemiringan suatu fungsi juga dikenal sebagai gradiennya. Semakin curam kemiringannya, semakin cepat model dapat mempelajarinya, dan semakin tinggi pula gradiennya. Sebaliknya, model akan berhenti belajar jika kemiringannya nol. Gradien digunakan untuk mengukur perubahan semua bobot sehubungan dengan perubahan kesalahan.
Exploding Gradient: Meledaknya gradien terjadi ketika algoritme memberikan bobot prioritas yang sangat tinggi tanpa alasan yang jelas. Untungnya, memotong atau menghilangkan gradien adalah solusi sederhana untuk masalah ini.
Vanishing Gradient: Gradien hilang terjadi ketika nilai gradien terlalu kecil, menyebabkan model berhenti belajar atau memakan waktu terlalu lama. Ini adalah masalah besar pada tahun 1990an, dan jauh lebih sulit untuk diatasi dibandingkan dengan ledakan gradien. Untungnya, konsep LSTM Sepp Hochreiter dan Juergen Schmidhuber memecahkan masalah tersebut.
Aplikasi RNN
Jaringan Neural Berulang digunakan untuk mengatasi berbagai masalah yang melibatkan data urutan. Ada berbagai jenis data urutan, namun yang paling umum adalah yang berikut ini: Urutan Audio, Teks, Video, dan Biologis.
Dengan menggunakan model RNN dan kumpulan data urutan, Anda dapat mengatasi berbagai masalah, termasuk :
Pengenalan suara
Generasi musik
Terjemahan Otomatis
Analisis aksi video
Studi urutan genom dan DNA
Kesimpulan
Jaringan Neural Berulang adalah alat serbaguna yang dapat digunakan dalam berbagai situasi. Mereka digunakan dalam berbagai metode untuk pemodelan bahasa dan generator teks. Mereka juga digunakan dalam pengenalan suara.
Jenis jaringan saraf ini digunakan untuk membuat label pada gambar yang tidak diberi tag saat dipasangkan dengan Jaringan Syaraf Konvolusional. Sungguh menakjubkan betapa baik kombinasi ini bekerja.
Namun, ada satu kelemahan pada jaringan saraf berulang. Mereka kesulitan mempelajari ketergantungan jangka panjang, yang berarti mereka tidak memahami hubungan antar data yang dipisahkan oleh beberapa langkah.
Saat mengantisipasi kata-kata, misalnya, kita mungkin memerlukan lebih banyak konteks daripada sekadar satu kata sebelumnya. Hal ini dikenal sebagai masalah gradien hilang, dan diselesaikan dengan menggunakan jenis Jaringan Neural Berulang khusus yang disebut Jaringan Memori Jangka Pendek (LSTM), yang merupakan topik lebih luas yang akan dibahas di artikel mendatang.
Last updated
Was this helpful?