
Gambar 1. IBM Type 11 Electric Keypunch
(Credit: blog post)
Gambar 1. IBM Type 11 Electric Keypunch
(Credit: blog post)
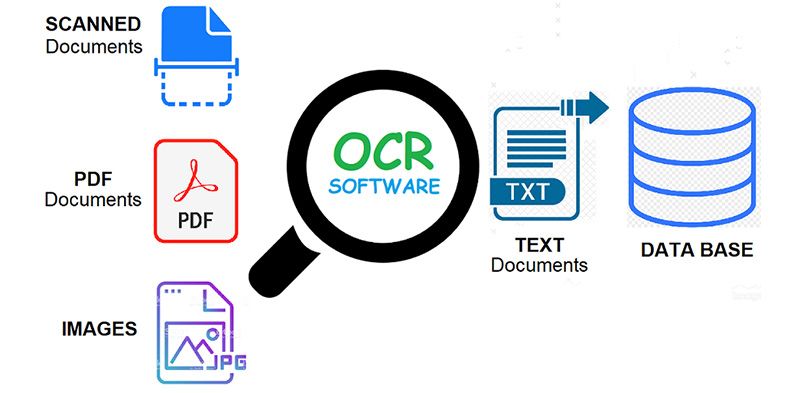
Proses Optical Character Recognition

Alur Proses OCR untuk membangun API dengan Tesseract
credit: blog post

Proses Tesseract 3 OCR
credit: Paper

Tesseract dengan LSTM
Credit: tesseract docs