# Praktikum 3
### Pembuatan Dataset Sintetis
Untuk mempelajari DBSCAN, kita akan membuat dataset sederhana berupa 3 klaster buatan menggunakan fungsi [`make_blobs`](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_blobs.html#sklearn.datasets.make_blobs) dari Scikit-Learn.
```python
from sklearn.datasets import
from sklearn.preprocessing import
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = (
n_samples=750, centers=centers, cluster_std=0.4, random_state=0
)
X = ().fit_transform(X)
```
Visualisasikan data yang dihasilkan dengan cara ini:
```python
import matplotlib.pyplot as plt
(X[:, 0], X[:, 1])
()
```
### Compute DBSCAN
Sekarang kita terapkan DBSCAN pada data tersebut.
Label yang ditetapkan oleh [`DBSCAN`](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html#sklearn.cluster.DBSCAN) dapat diakses melalui atribut `labels_`. Titik data yang dianggap *noise* akan diberi label khusus.
```python
import numpy as np
from sklearn import metrics
from sklearn.cluster import
db = (eps=0.3, min_samples=10).fit(X)
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
```
> * `eps=0.3` → jarak maksimum antar titik untuk dianggap tetangga.
> * `min_samples=10` → jumlah minimum titik dalam radius `eps` agar dianggap area padat (core sample).
> * Label hasil klasterisasi tersedia di `labels`. Nilai `-1` berarti titik tersebut dianggap **noise** atau **outlier**.
```python
Estimated number of clusters: 3
Estimated number of noise points: 18
```
### Evaluasi Kualitas Klasterisasi
Karena kita menggunakan dataset sintetis (`make_blobs`), kita tahu label aslinya (`labels_true`). Ini memungkinkan kita mengukur kualitas DBSCAN dengan berbagai metrik evaluasi.
```python
print(f"Homogeneity: {(labels_true, labels):.3f}")
print(f"Completeness: {(labels_true, labels):.3f}")
print(f"V-measure: {(labels_true, labels):.3f}")
print(f"Adjusted Rand Index: {(labels_true, labels):.3f}")
print(
"Adjusted Mutual Information:"
f" {(labels_true, labels):.3f}"
)
print(f"Silhouette Coefficient: {(X, labels):.3f}")
```
```python
Homogeneity: 0.953
Completeness: 0.883
V-measure: 0.917
Adjusted Rand Index: 0.952
Adjusted Mutual Information: 0.916
Silhouette Coefficient: 0.626
```
> * **Homogeneity** → apakah tiap klaster hanya berisi satu label asli.
> * **Completeness** → apakah semua sampel dengan label asli yang sama masuk ke klaster yang sama.
> * **V-measure** → rata-rata harmonik dari homogeneity dan completeness.
> * **Adjusted Rand Index (ARI)** → kesesuaian antara klasterisasi dengan label asli.
> * **Adjusted Mutual Information (AMI)** → kesamaan informasi antara klasterisasi dengan label asli.
> * **Silhouette Coefficient** → seberapa baik data dikelompokkan (nilai mendekati 1 berarti bagus, mendekati 0 berarti berada di batas, negatif berarti salah klaster).
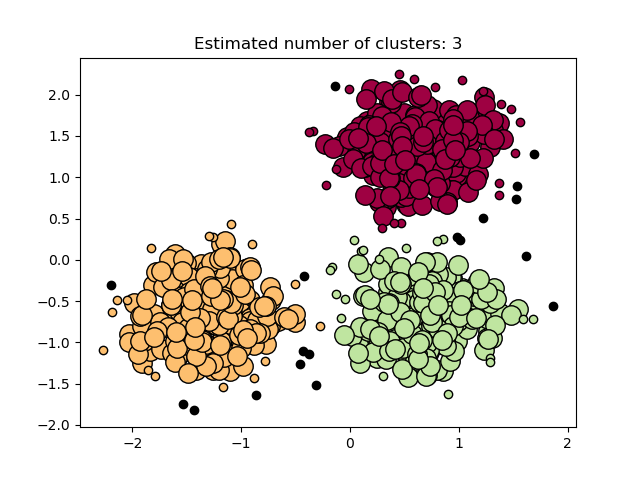
### Visualisasi Hasil Klasterisasi
Kita akan memvisualisasikan hasil DBSCAN.
* **Core sample** ditampilkan dengan titik besar.
* **Non-core sample** ditampilkan dengan titik kecil.
* **Noise** ditampilkan dengan warna hitam.
```python
unique_labels = set(labels)
core_samples_mask = (labels, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
colors = [plt.cm.Spectral(each) for each in (0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
# Black used for noise.
col = [0, 0, 0, 1]
class_member_mask = labels == k
xy = X[class_member_mask & core_samples_mask]
(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=14,
)
xy = X[class_member_mask & ~core_samples_mask]
(
xy[:, 0],
xy[:, 1],
"o",
markerfacecolor=tuple(col),
markeredgecolor="k",
markersize=6,
)
(f"Estimated number of clusters: {n_clusters_}")
()
```
> 👉 **Interpretasi visual:**
>
> * Titik besar berwarna → **core samples** dalam klaster.
> * Titik kecil berwarna → **non-core samples**, tetap termasuk klaster.
> * Titik hitam → **noise/outlier**.