# DBSCAN Clustering
### **Definisi**
**DBSCAN** adalah algoritma klasterisasi berbasis kepadatan (*density-based clustering algorithm*) yang bertujuan menemukan kelompok data (klaster) sebagai **wilayah dengan kepadatan tinggi** yang dipisahkan oleh wilayah berkepadatan rendah. Berbeda dengan algoritma berbasis centroid (misalnya K-Means), DBSCAN tidak memerlukan informasi jumlah klaster sejak awal, dan dapat mengenali bentuk klaster yang tidak teratur.
Algoritma **DBSCAN** memandang klaster sebagai wilayah dengan kepadatan tinggi yang terpisah oleh wilayah dengan kepadatan rendah. Karena definisi yang cukup umum ini, DBSCAN mampu menemukan klaster dengan bentuk apa saja, berbeda dengan **k-means** yang hanya mampu mengenali klaster berbentuk konveks. Komponen utama dari DBSCAN adalah konsep **core sample**, yaitu data yang berada di area padat. Dengan demikian, sebuah klaster dalam DBSCAN terbentuk dari kumpulan core sample yang saling berdekatan, ditentukan berdasarkan ukuran jarak tertentu, serta kumpulan **non-core sample** yang posisinya dekat dengan core sample, meskipun tidak termasuk core sample itu sendiri.
Algoritma DBSCAN memiliki dua parameter:
* **min\_samples**
* **eps** (*epsilon*)
Kedua parameter ini mendefinisikan secara formal apa yang dimaksud dengan “padat”. Nilai **min\_samples** yang lebih tinggi atau **eps** yang lebih rendah menunjukkan bahwa diperlukan kepadatan yang lebih tinggi untuk membentuk sebuah klaster.
Secara formal, sebuah core sample didefinisikan sebagai data dalam sebuah dataset yang memiliki setidaknya *min\_samples* tetangga dalam radius *eps*. Sampel-sampel tetangga ini disebut sebagai **neighbors** dari core sample tersebut. Hal ini menunjukkan bahwa core sample berada di area dengan kepadatan tinggi dalam ruang vektor. Klaster kemudian dibangun secara rekursif, dimulai dari satu core sample, lalu mencari semua neighbors yang juga core sample, kemudian mencari neighbors mereka, dan seterusnya. Selain core sample, sebuah klaster juga mencakup **non-core sample**, yaitu data yang merupakan tetangga dari core sample di dalam klaster, tetapi bukan core sample itu sendiri. Data semacam ini dapat dianggap berada di pinggiran klaster.
Setiap core sample secara definisi akan selalu menjadi bagian dari sebuah klaster. Sebaliknya, jika sebuah data bukan core sample dan berjarak lebih dari *eps* terhadap seluruh core sample, maka data tersebut dianggap sebagai **outlier** oleh algoritma.
Dari sisi parameter, ***min\_samples*** berfungsi untuk mengatur seberapa toleran algoritma terhadap **noise**. Pada dataset yang besar dan penuh *noise*, biasanya nilai ini dibuat lebih tinggi agar hasil klasterisasi lebih stabil. Sementara itu, parameter ***eps*** memiliki peran yang sangat krusial. Nilai ini menentukan ukuran lingkungan lokal dari setiap titik, sehingga pemilihannya harus disesuaikan dengan dataset dan fungsi jarak yang digunakan.
* Jika **eps terlalu kecil**, sebagian besar data tidak akan masuk ke klaster (dan diberi label **–1** untuk “noise”).
* Jika **eps terlalu besar**, klaster yang berdekatan bisa bergabung menjadi satu klaster besar, bahkan seluruh dataset bisa dianggap sebagai satu klaster tunggal.
Beberapa literatur menyarankan **heuristik** untuk memilih parameter ini, misalnya dengan mencari “siku” (*knee*) pada grafik jarak nearest neighbor. Pada ilustrasi berikut menunjukan bahwa:
* Warna menunjukkan **keanggotaan klaster**.
* **Lingkaran besar** → core sample yang ditemukan algoritma.
* **Lingkaran kecil** → non-core sample yang tetap menjadi bagian dari klaster.
* **Titik hitam** → outlier yang terdeteksi.
### **Cara Kerja DBSCAN**
1. Untuk setiap data (instance), algoritma menghitung berapa banyak data lain yang berada dalam jarak tertentu *epsilon (ε / eps)*. Wilayah ini disebut **ε-neighborhood** dari data tersebut.
2. Jika sebuah data memiliki paling sedikit **min\_samples** data di dalam **ε-neighborhood** (termasuk dirinya sendiri), maka data tersebut disebut **core instance**. Core instance adalah data yang berada di wilayah padat.
3. Semua data yang berada dalam neighborhood dari core instance dimasukkan ke dalam klaster yang sama. Jika neighborhood ini mencakup core instance lain, maka mereka akan bergabung menjadi satu klaster besar.
4. Data yang tidak memenuhi kriteria sebagai core instance, dan juga tidak berada dalam neighborhood core instance lain, dianggap sebagai **anomali (outlier)**.
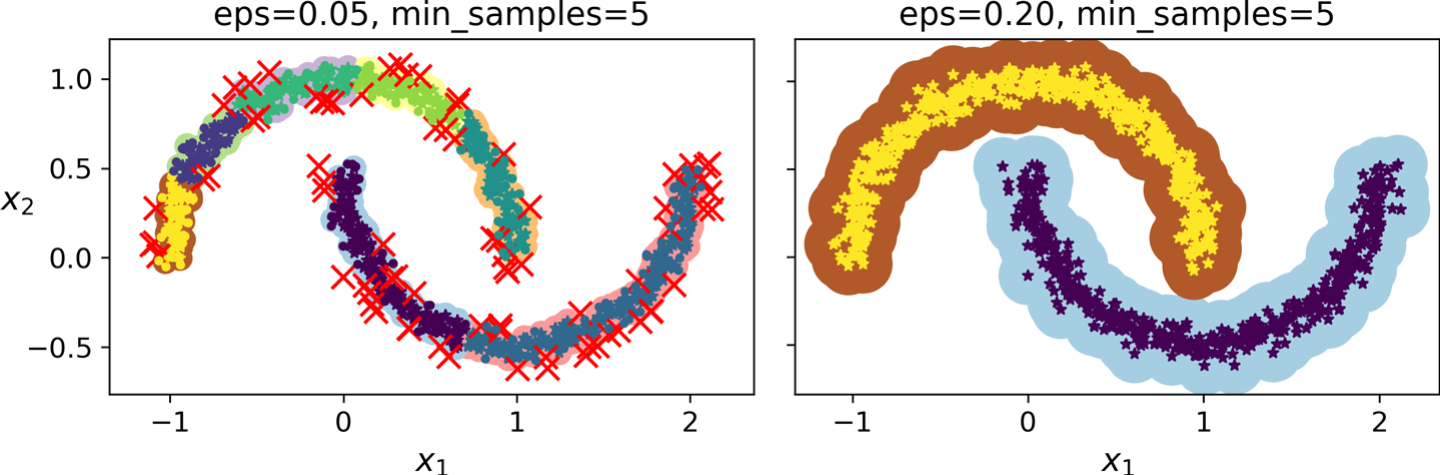
DBSCAN clustering using two different neighborhood radiuses
Gambar diatas menunjukkan bagaimana sebuah algoritma klastering DBSCAN bekerja untuk mengelompokkan data. Tujuan utamanya adalah untuk menemukan kelompok-kelompok data yang padat, sekaligus mengabaikan data-data yang terisolasi atau berada di luar kelompok tersebut.
Pada gambar, kita melihat dua skenario dengan pengaturan yang berbeda:
* Gambar Kiri (Terlalu Sensitif): Algoritma terlalu "pelit" dalam mengelompokkan data. Akibatnya, data yang seharusnya menjadi satu kelompok justru terpecah-pecah menjadi banyak kelompok kecil. Titik-titik yang terpisah dari kelompok lain (ditandai `x` merah) dianggap sebagai titik *noise* atau data yang tidak termasuk kelompok mana pun.
* Gambar Kanan (Pengaturan Tepat): Algoritma diatur dengan lebih "longgar." Dengan pengaturan ini, ia berhasil mengenali dan menggabungkan data yang seharusnya menjadi satu kelompok besar, membentuk dua klaster utama yang akurat (dua bulan sabit). Titik-titik yang sebelumnya dianggap *noise* kini berhasil dimasukkan ke dalam kelompok yang sesuai.
Secara umum, gambar tersebut menjelaskan bahwa keberhasilan algoritma DBSCAN sangat bergantung pada pengaturan parameternya. Pengaturan yang tidak tepat bisa membuat algoritma gagal mengenali kelompok yang sebenarnya, sementara pengaturan yang pas akan menghasilkan pengelompokan yang akurat dan logis.
### **Karakteristik DBSCAN**
* Tidak perlu menentukan jumlah klaster di awal, berbeda dengan K-Means.
* Mampu mengenali klaster berbentuk bebas (tidak terbatas pada bentuk lingkaran atau bola).
* Robust terhadap outlier, karena data yang tidak cocok dengan klaster manapun otomatis ditandai sebagai anomali.
* Memiliki dua hyperparameter utama:
* epsilon (ε / eps) → jarak maksimum untuk menentukan tetangga.
* min\_samples → jumlah minimum data di dalam *neighborhood* untuk membentuk sebuah klaster.
* Kompleksitas komputasi DBSCAN adalah sekitar `O(m log m)` namu, kebutuhan memori bisa sangat tinggi jika nilai epsilon (ε) terlalu besar.
### **Perbandingan DBSCAN dan K-Means**
| Aspek | **K-Means** | **DBSCAN** |
| --------------------- | -------------------------------------------------------------- | ------------------------------------------------------------------------- |
| **Jumlah Klaster** | Harus ditentukan sejak awal (kk). | Tidak perlu ditentukan; klaster terbentuk berdasarkan kepadatan. |
| **Bentuk Klaster** | Baik untuk klaster berbentuk bulat/sferis. | Bisa mengenali klaster dengan bentuk bebas dan tidak beraturan. |
| **Outlier** | Tidak ditangani, outlier dipaksa masuk ke klaster. | Outlier otomatis ditandai sebagai anomali (−1-1). |
| **Parameter** | Hanya jumlah klaster (kk). | Dua parameter: ε\varepsilon (*eps*) dan **min\_samples**. |
| **Kompleksitas** | Cepat dan efisien, tetapi sensitif pada inisialisasi centroid. | Sedikit lebih berat komputasi, tetapi lebih stabil terhadap variasi data. |
| **Kepadatan Berbeda** | Tidak bisa menangani variasi kepadatan dengan baik. | Bisa gagal juga jika perbedaan kepadatan antar klaster terlalu besar. |
> * Gunakan **K-Means** jika: jumlah klaster sudah diketahui, data relatif seimbang, dan bentuk klaster mendekati bulat.
> * Gunakan **DBSCAN** jika: jumlah klaster tidak diketahui, bentuk klaster tidak teratur, dan ingin mendeteksi outlier secara otomatis.