# Praktikum 4
## Pengantar
Setelah kita memahami proses klasifikasi dengan menggunakan SVM, selanjutnya kita akan belajar melakukan klasifikasi dengan data riil berupa citra wajah. Dataset yang akan digunakan adalah dataset wajah-wajah dari ribuan publik figur.
NB: Anda mungkin memerlukan waktu yang cukup lama untuk mengunduh dataset.
## Langkah 0 - Unduh Dataset
Dataset yang digunakan dapat diunduh secara langsung melalui scikit-learn.
{% code overflow="wrap" lineNumbers="true" %}
```python
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
print(faces.target_names)
print(len(faces.target_names))
print(faces.images.shape)
```
{% endcode %}
## Langkah 1 - Inspeksi Citra Wajah
Lakukan inspeksi citra wajah yang akan digunakan.
{% code overflow="wrap" lineNumbers="true" %}
```python
# contoh wajah yang digunakan
from matplotlib import pyplot as plt
fig, ax = plt.subplots(3, 5)
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='bone')
axi.set(xticks=[], yticks=[],
xlabel=faces.target_names[faces.target[i]])
```
{% endcode %}
Didapatkan ilustrasi,
## Langkah 2 - Pra Pengolahan Data
Pada tahap ini, kita akan mencoba melakukan proses pra pengolahan data sederhana dengan menggunakan Principal Component Analysis (PCA). PCA akan memproyeksikan fitur dengan rosolusi tinggi (banyak dimensi) ke dalam *principal component* atau fitur yang dianggap penting saja. Metode PCA sering juga disebut sebagai metode reduksi dimensi.
{% code overflow="wrap" lineNumbers="true" %}
```python
from sklearn.svm import SVC
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.pipeline import make_pipeline
pca = RandomizedPCA(n_components=150, whiten=True, random_state=42)
svc = SVC(kernel='rbf', class_weight='balanced')
# Pipeline digunakan untuk melakukan proses secara bertahap dalam
# 1 eksekusi fungsi secara langsung
model = make_pipeline(pca, svc)
```
{% endcode %}
## Langkah 3 - Split Data
{% code lineNumbers="true" expandable="true" %}
```python
# pemisahan data training dan data testing
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(faces.data, faces.target, random_state=42)
```
{% endcode %}
## Langkah 4 - Pembuatan Model + Tunning
Pada langkah ini, kita akan mensimulasikan pembuatan model dan hyperparameter tunning secara langsung untuk mendapatkan nilai hyperparameter yang terbaik. Nilai tersebut dapat dicapai salah satunya dengan menggunakan teknik `GridSearch`. GridSearch akan mencoba menjadi kombinasi hyperparameter terbaik dengan cara melakukan pengujian performansinya satu per satu. Cara ini mudah akan tetapi memakan waktu yang lama dan komputasi yang cukup tinggi.
{% code overflow="wrap" lineNumbers="true" %}
```python
from sklearn.model_selection import GridSearchCV
param_grid = {'svc__C': [1, 5, 10, 50],
'svc__gamma': [0.0001, 0.0005, 0.001, 0.005]}
grid = GridSearchCV(model, param_grid)
%time grid.fit(Xtrain, ytrain)
print(grid.best_params_)
print(grid.best_score_)
```
{% endcode %}
Didapatkan,
```
CPU times: user 1min 56s, sys: 3.56 s, total: 2min
Wall time: 17.1 s
{'svc__C': 5, 'svc__gamma': 0.001}
0.828893332683022
```
Sehingga didapatkan informasi bahwa, hyperparameter terbaik dari model SVM yang kita buat adalah dengan, C=5 dan Gamma=0.001 dengan tingkat akurasi 82.88%.
Gunakan model terbaik tersebut untuk proses prediksi.
{% code lineNumbers="true" expandable="true" %}
```python
model = grid.best_estimator_
yfit = model.predict(Xtest)
```
{% endcode %}
## Langkah 5 - Cek Hasil Prediksi
Cek hasil prediksi pada citra.
{% code overflow="wrap" lineNumbers="true" %}
```python
# hasil label pada data testing
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],
color='black' if yfit[i] == ytest[i] else 'red')
fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14)
```
{% endcode %}
Didapatkan,
Contoh di atas hanya menunjukkan satu data dengan label salah. Selanjutnya, kita akan mengukur performa model dengan ***classification report*** dan ***confusion matrix***.
## Langkah 6 - Cek Performansi
Pertama, cek performansi dengan `classification_report` dari sklearn.
{% code overflow="wrap" lineNumbers="true" %}
```python
from sklearn.metrics import classification_report
print(classification_report(ytest, yfit,
target_names=faces.target_names))
```
{% endcode %}
Didapatkan,
```
precision recall f1-score support
Ariel Sharon 0.65 0.87 0.74 15
Colin Powell 0.83 0.88 0.86 68
Donald Rumsfeld 0.70 0.84 0.76 31
George W Bush 0.97 0.80 0.88 126
Gerhard Schroeder 0.76 0.83 0.79 23
Hugo Chavez 0.93 0.70 0.80 20
Junichiro Koizumi 0.86 1.00 0.92 12
Tony Blair 0.82 0.98 0.89 42
accuracy 0.85 337
macro avg 0.82 0.86 0.83 337
weighted avg 0.86 0.85 0.85 337
```
Dari tabel tersebut, kita mendapatkan informasi terkait dengan akurasi keseluruhan, presisi, recall, dan f1-score untuk setiap label.
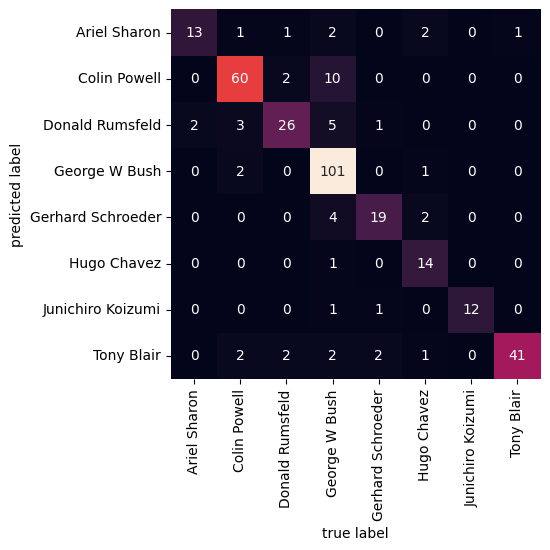
Selanjutnya, kita dapat menggunakan confusion matrix untuk mengetahui label label yang terklasifikasi dengan benar dan tidak.
{% code overflow="wrap" lineNumbers="true" %}
```python
# bentuk confusion matrix
from sklearn.metrics import confusion_matrix
import seaborn as sns
mat = confusion_matrix(ytest, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label')
```
{% endcode %}