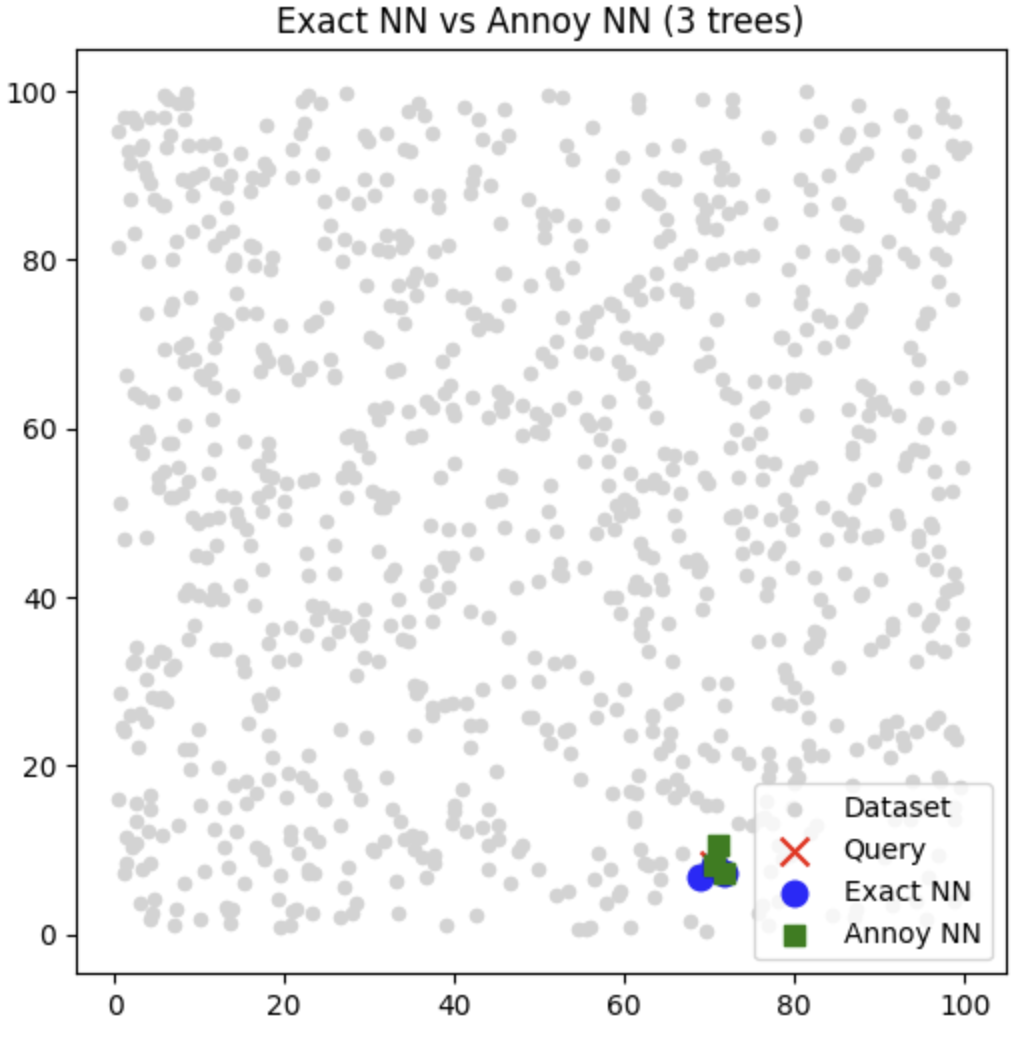

| Distance Metrics | Tree | Jumlah data | Hasil Index terdekat ENN vs ANN | Waktu komputasi Vs |
|---|---|---|---|---|
| Euclidean | 3 | 1000 | [219 898 593], [219 898 770] | 1.2271 , 0.1264 |
| Euclidean | 8 | 1000 | ... | ... |
| Euclidean | 3 | 100,000 | ... | ... |
| Angular | 3 | 1000 | ... | ... |
| Angular | 8 | 1000 | ... | ... |
| Angular | 3 | 100,000 | ... | ... |
| Distance Metrics | Tree | Jumlah data | Hasil Index terdekat ENN vs ANN | Waktu komputasi Vs |
|---|---|---|---|---|
| Euclidean | 8 | 1000000 | ... | ... |
| Angular | 8 | 1000000 | ... | ... |