# Praktikum 2
Pada tahap ini kita akan melakukan Pre- Processing sebelum melakukan seleksi Fitur. Pre processing akan melakukan encoding pada data-data kategorikal, yaitu "Sex" dan "Cabin", imputasi data pada "Age", standarisasi pada fitur "Age". Hal ini perlu dilakukan karena algoritma pembelajaran mesin melakukan proses kalkulasi secara matematis. Salah satu strategi yang bisa di gunakan adalah **Label Encoding**. Label Encoding serupa dengan Ordinal Encoding, bedanya hanya pada proses pengurutan. Label Encoding tidak mengurutkan data terlebih dahulu.
Setelah pre Processing selesai, langkah selanjutnya memilih variabel mana saja yang akan kita gunakan sebagai fitur. Pada bagian dasar teori, kita sudah mempelajari bahwa tidak selalu semua variabel dapat digunakan sebagai fitur. Oleh karena itu, kita dapat memilih fitur yang sekiranya penting untuk tujuan yang ingin kita capai dalam membuat model pembelajaran mesin. Kita akan menggunakan kasus yang sama, yaitu kita kita mengetahui ciri-ciri penumpang kapal Titanic yang selamat. Sehingga, fitur yang kita gunakan adalah,
1. "**Survived**"
2. "**Pclass**"
3. "**Sex**"
4. "**Age**"
5. "**Cabin**"
Kita akan memisahkan variabel-variabel tersebut dari variabel yang lain.
Data yang akan kita gunakan adalah data Titanic yang sudah diperbaiki dengan proses imputasi.
:arrow\_down: **Download** :arrow\_down:
[66KBTitanic-Dataset-fixed.csv](https://1473714265-files.gitbook.io/~/files/v0/b/gitbook-x-prod.appspot.com/o/spaces%2Fhh7WzzoZbeFX9VC0bZSU%2Fuploads%2FkxFyYw02z3kTMz1ZPgyU%2FTitanic-Dataset-fixed.csv?alt=media\&token=79534cd0-6428-4192-b147-6435401209ab)
#### Langkah 0 - Load Library
```python
import pandas as pd
from sklearn.preprocessing import LabelEncoder, StandardScaler
```
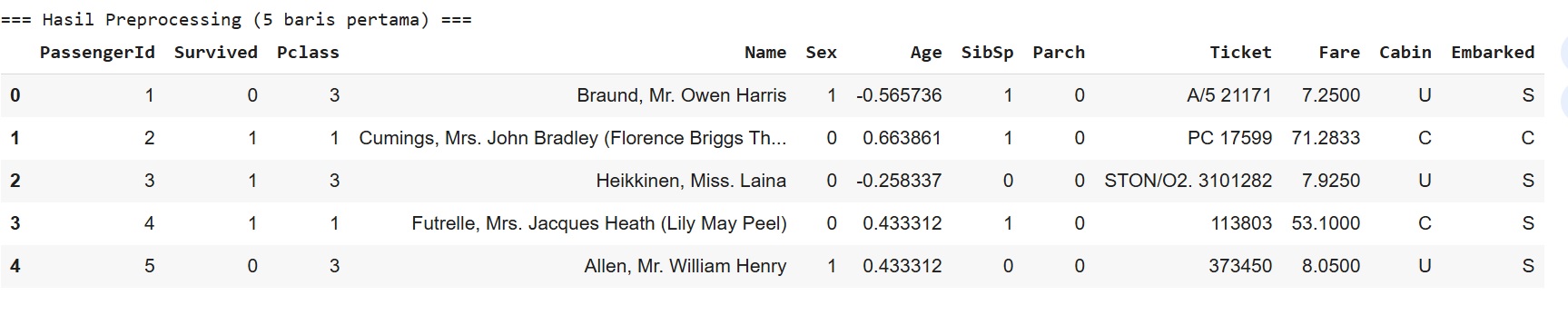
#### Langkah 1 - Load Data
```python
dpath = 'data/Titanic-Dataset-fixed.csv'
df = pd.read_csv(dpath)
df.head()
```
Hasil tampilan
#### Langkah 2 - Pre Processing Encoding Sex
Pada tahap ini akan melakukan encoding pada data-data kategorikal, yaitu "Sex"
```python
# --- 2. Encoding fitur 'Sex' ---
df['Sex'] = df['Sex'].map({'male': 1, 'female': 0})
print("=== Hasil Setelah Encoding 'Sex' ===")
print(df[['Sex']].head(), "\n")
```
**Langkah 3 - Verifikasi hasil encoding "sex"**
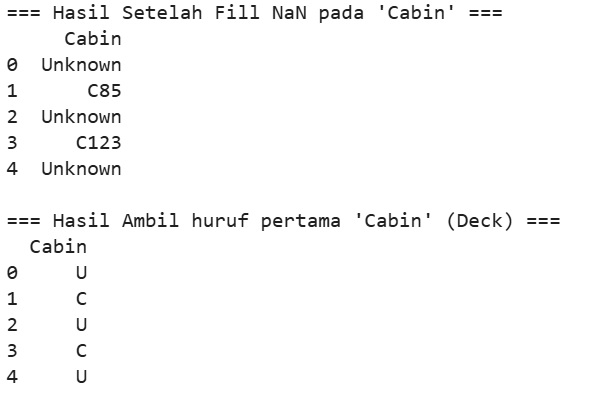
**Langkah 4- Pre Processing Encoding "Cabin".**
Pada tahap ini akan melakukan encoding pada data-data kategorikal, yaitu "Cabin"
```notebook-python
# --- 3. Encoding fitur 'Cabin' ---
df['Cabin'] = df['Cabin'].fillna('Unknown')
print("=== Hasil Setelah Fill NaN pada 'Cabin' ===")
print(df[['Cabin']].head(5), "\n")
df['Cabin'] = df['Cabin'].apply(lambda x: x[0] if x != 'Unknown' else 'U')
print("=== Hasil Ambil huruf pertama 'Cabin' (Deck) ===")
print(df[['Cabin']].head(5), "\n")
```
**Langkah 5 - Verifikasi hasil encoding "Cabin"**
Langkah 5 - Pre Processing Imputasi Data
Pada tahapan ini kita akan melakukan imputasi data pada "Age". Tujuan dari langkah ini adalah untuk demonstrasi proses imputasi data dengan nilai **median**.
```notebook-python
# --- 4. Standarisasi fitur 'Age' ---
df['Age'] = df[['Age']].fillna(df['Age'].median())
print("=== Hasil Setelah Imputasi Data pada Usia dengan median ===")
print(df[['Age']].head(10), "\n")
```
#### Langkah 6 - Verifikasi Hasil Imputasi Data
Langkah 7 - Pre Processing Standarisasi
Pada tahapan ini kita akan melakukan standarisasi pada "Age". **Hal ini sebetulnya tidak terlalu diperlukan karena nilai pada "Age" tidak terlalu jauh.** Tujuan dari langkah ini adalah untuk demonstrasi proses standarisasi.
```python
scaler = StandardScaler()
df['Age'] = scaler.fit_transform(df[['Age']])
print("=== Hasil Setelah Standardisasi 'Age' ===")
print(df[['Age']].head(10), "\n")
```
#### Langkah 6 - Verifikasi Hasil Standarisasi
Cek kembali dengan `df.head()`. Hasilnya akan seperti pada Gambar dibawah ini.
Hasil Standarisasi
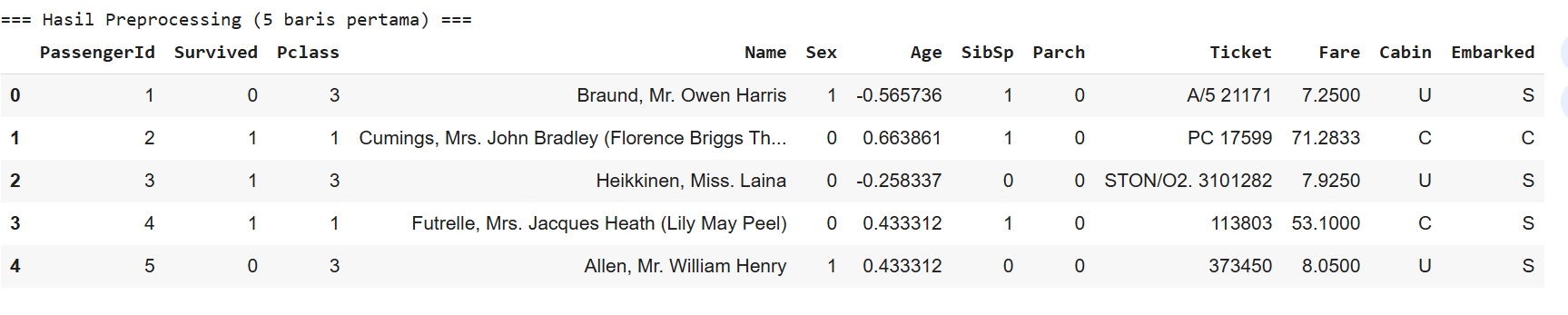
#### Langkah 7 - Hasil setelah Pre Processing
Pada tahapan ini, akan melakukan pengecekan hasil Pre Processing yang sudah dilakukan yaitu Encoding pada fitur "Sex" dan "Cabin", imputasi data pada "Age", standarisasi pada fitur "Age".
```notebook-python
# --- 5. Cek hasil akhir ---
print("=== Hasil Preprocessing (5 baris pertama) ===")
#print(df[['Sex', 'Cabin', 'Age']].head(5))
df.head()
```
#### Langkah 8 - Verifikasi Hasil setelah Pre Processing
#### Langkah 9 - Seleksi Fitur
pada tahap ini akan dipilih 5 variabel sebagai fitur penting yaitu fitur **"Survived". "Pclass", "Age", "Sex"**, dan **"Cabin".**
```python
df = df[['Survived', 'Pclass', 'Age', 'Sex', 'Cabin']]
df.head()
```
Verifikasi Hasil Seleksi Fitur
### Kode Lengkap
{% file src="" %}